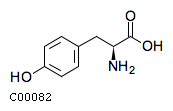
Entry Name L-Tyrosine;
Formula C9H11NO3
Exact mass 181.0739
Mol weight 181.19
Structure Mol file KCF file DB search Remark Reaction Pathway map00130 Ubiquinone and other terpenoid-quinone biosynthesis
map00400 Phenylalanine, tyrosine and tryptophan biosynthesis
map00950 Isoquinoline alkaloid biosynthesis
map00997 Biosynthesis of various other secondary metabolites
map00998 Biosynthesis of various antibiotics
map00999 Biosynthesis of various plant secondary metabolites
map01055 Biosynthesis of vancomycin group antibiotics
map01059 Biosynthesis of enediyne antibiotics
map01060 Biosynthesis of plant secondary metabolites
map01063 Biosynthesis of alkaloids derived from shikimate pathway
map01110 Biosynthesis of secondary metabolites
map01210 2-Oxocarboxylic acid metabolism
map04974 Protein digestion and absorption
map05230 Central carbon metabolism in cancer
Module M00025 Tyrosine biosynthesis, chorismate => HPP => tyrosine
M00039 Monolignol biosynthesis, phenylalanine/tyrosine => monolignol
M00040 Tyrosine biosynthesis, chorismate => arogenate => tyrosine
M00042 Catecholamine biosynthesis, tyrosine => dopamine => noradrenaline => adrenaline
M00043 Thyroid hormone biosynthesis, tyrosine => triiodothyronine/thyroxine
M00044 Tyrosine degradation, tyrosine => homogentisate
M00127 Thiamine biosynthesis, prokaryotes, AIR (+ DXP/tyrosine) => TMP/TPP
M00369 Cyanogenic glycoside biosynthesis, tyrosine => dhurrin
M00827 C-1027 beta-amino acid moiety biosynthesis, tyrosine => 3-chloro-4,5-dihydroxy-beta-phenylalanyl-PCP
M00828 Maduropeptin beta-hydroxy acid moiety biosynthesis, tyrosine => 3-(4-hydroxyphenyl)-3-oxopropanoyl-PCP
M00889 Puromycin biosynthesis, ATP => puromycin
M00935 Methanofuran biosynthesis
M00961 Betacyanin biosynthesis, L-tyrosine => amaranthin
Network nt06016 Phenylalanine and tyrosine metabolism
nt06028 Dopamine and serotonin metabolism
nt06322 TRH-TSH-TH signaling
nt06463 Parkinson disease
nt06544 Neuroactive ligand signaling
Enzyme Brite Compounds with biological roles [BR:br08001 ]br08311 ] BRITE hierarchy Other DBs LinkDB All DBs KCF data Show